Training Guide
Welcome to Mouse vs. AI: Robust Visual Foraging Challenge @ NeurIPS 2025
This is a general training guide for the Mouse vs. AI NeurIPS 2025 competition.
For platform-specific instructions on how to download the environment and train an agent, please check: Windows, Linux and macOS
General instructions
The task for virtual and biological agents is to reach a randomly placed target within a time window of 5 seconds. At the beginning of the training, the target was placed close to the mice, and the target distance was increased incrementally when the agents achieved a 70% success rate. Mice were trained under normal conditions before their performance under unseen visual perturbations was tested.
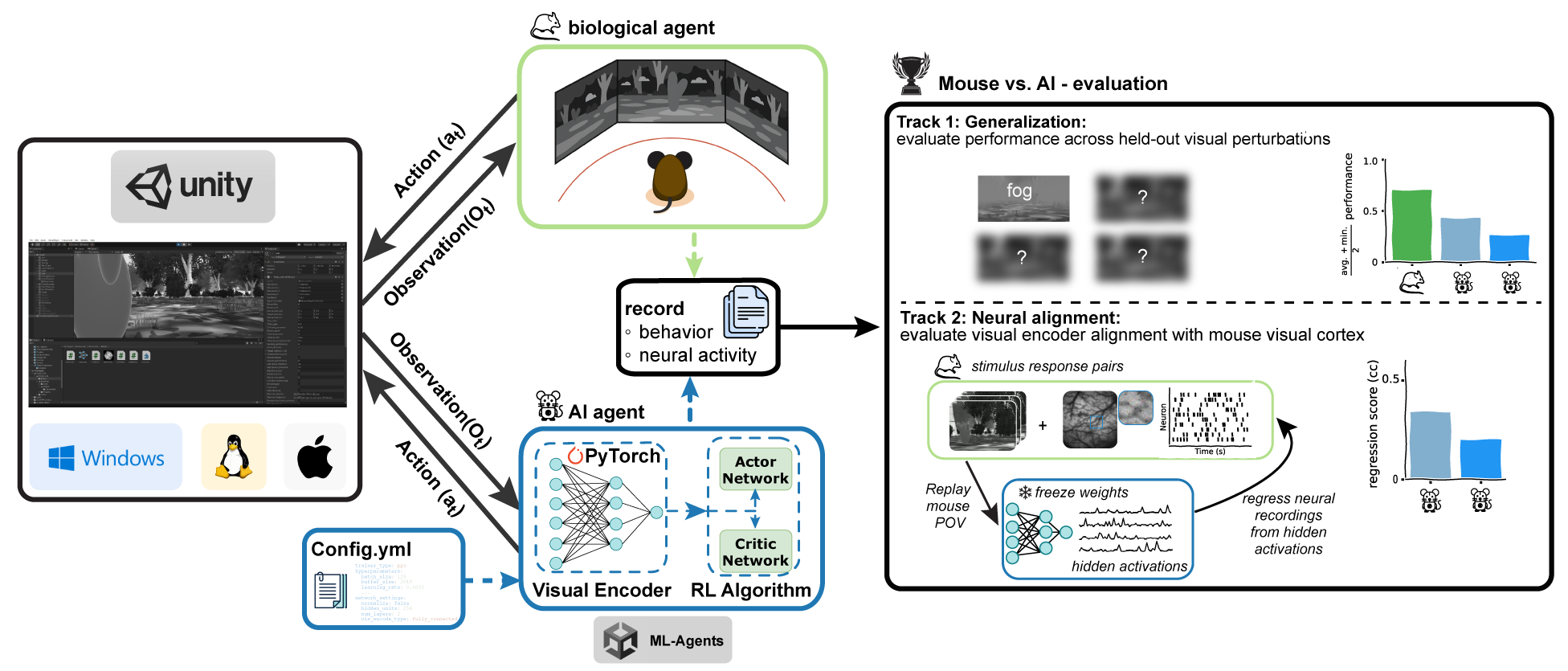
Environment Builds
We provide 4 different builds, 3 are mainly intended for training, and 1 for testing, but you can use them in any way you wish.
Training Environments
The three training environments (NormalTrain, FogTrain, and RandomTrain) share a progressive difficulty mechanism. Initially, the target is placed close to the agent’s starting point. Upon achieving a 70% success rate, the target distance automatically increases, ultimately reaching the maximum distance of 5 units. All training builds present the same core task, differing only in their visual rendering:
- NormalTrain: Features an unperturbed, standard visual scene.
- FogTrain: Consists solely of visual scenes with fog trails.
- RandomTrain: Alternates between normal and fog trail visual conditions.
Testing Environments
Moreover, the RandomTest build is intended for you to get an idea of how well your agent performs. The RandomTest build starts with the target being randomly placed at maximum distance and alternates trials between the two provided conditions (normal and fog).
Training with ML-Agents
ML-Agents
- Agent: The agent acts as the primary entity interacting with the environment. It passes its observations to its Policy, which then processes this information, makes a decision, and sends the chosen action back to the agent for execution.
- Decisions: The observation-decision-action-reward cycle repeats each time the Agent requests a decision. Decision-making for our agents occurs every 5 steps.
- Observation: The agent receives Visual observations via a CameraSensor. This sensor provides image information as a 155 × 86 x 1 3D tensor, ready to be processed by the agent’s visual encoders.
- Actions: An action is an instruction from the Policy that the agent carries out. Our agent utilizes continuous actions, where its Policy outputs an action represented by two floating-point values.
- Rewards: Rewards serve as a crucial signal in reinforcement learning, indicating the desirability of an agent’s actions. The Proximal Policy Optimization (PPO) algorithm, which we employ, optimizes the agent’s choices to maximize the cumulative reward over time. Specifically, our agent receives a positive reward (+20f) upon reaching the target and a negative reward (−1f) for each action taken, encompassing both movement and rotation.
Training Configurations
| Setting | Description |
|---|---|
trainer_type |
(default = ppo) The type of trainer to use: ppo, sac, or poca. |
hyperparameters -> batch_size |
(default = 128) Number of experiences in each iteration of gradient descent. |
hyperparameters -> buffer_size |
(default = 2048) PPO: Number of experiences to collect before updating the policy model. Corresponds to how many experiences should be collected before we do any learning or updating of the model. This should be multiple times larger than batch_size. Typically, a larger buffer_size corresponds to more stable training updates. |
hyperparameters -> learning_rate |
(default = 3e-4) Initial learning rate for gradient descent. Corresponds to the strength of each gradient descent update step. This should typically be decreased if training is unstable, and the reward does not consistently increase. |
summary_freq |
Number of experiences that need to be collected before generating and displaying training statistics. This determines the granularity of the graphs in Tensorboard. |
max_steps |
Total number of steps (i.e., observation collected and action taken) that must be taken in the environment before ending the training process. |
keep_checkpoints |
The maximum number of model checkpoints to keep. Checkpoints are saved after the number of steps specified by the checkpoint_interval option. Once the maximum number of checkpoints has been reached, the oldest checkpoint is deleted when saving a new checkpoint. |
checkpoint_interval |
The number of experiences collected between each checkpoint by the trainer. A maximum of keep_checkpoints checkpoints are saved before old ones are deleted. Each checkpoint saves the .onnx files in the results/ folder. |
PPO-specific Configurations
| Setting | Description |
|---|---|
hyperparameters -> beta |
(default = 5.0e-3) Strength of the entropy regularization, which makes the policy “more random.” This ensures that agents properly explore the action space during training. Increasing this will ensure more random actions are taken. This should be adjusted such that the entropy (measurable from TensorBoard) slowly decreases alongside increases in reward. If entropy drops too quickly, increase beta. If entropy drops too slowly, decrease beta. Typical range: 1e-4 - 1e-2 |
hyperparameters -> epsilon |
(default = 0.2) Influences how rapidly the policy can evolve during training. Corresponds to the acceptable threshold of divergence between the old and new policies during gradient descent updating. Setting this value small will result in more stable updates, but will also slow the training process. Typical range: 0.1 - 0.3 |
For more details on training parameters, please refer to the official ML-Agents documentation page.
Evaluation
Once you submit a model, we will evaluate it by testing your agent’s performance on trials where the target is placed at the maximum distance on all provided + 3 additional held-out perturbations.
Track 1 will score your agent’s performance based on two metrics: the average success rate across all conditions (ASR) and the minimum success rate (MSR) across all conditions, to capture the worst-case generalization. The final score for track 1 will be calculated as follows:
Track 2 will be evaluated based on the ability of a linear regression model to predict neural responses from the agent’s visual encoders’ hidden activations. We will provide a track two evaluation script and a few minutes of data to allow you to assess your agents’ alignment with mouse visual cortex activity. The final evaluation is conducted on a held-out test set of stimulus-response pairs and quantified as the mean pearson correlation between predicted and recorded neural activity, averaged across all recorded neurons.